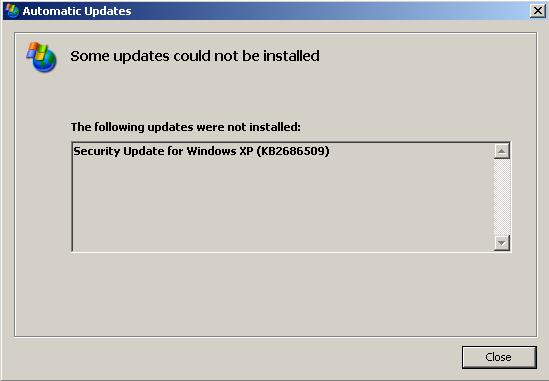
Is what I get for dutifully installing all updates?
Telling me that the install failed twice is nice, but does not hide the fact that I still don’t know why. I feel like I’m playing a guessing game with my 3 year old daughter: “I’m not telling!”
I know that if I go to IT they’ll want to reimage my machine. At first their predilection for reimaging bugged me as I thought more effort should go into figuring out the root cause. But over the years I’ve come to sympathize with their position. Usually after hours of probing you run into a brick wall, an OS bug or some silent failure and without source code there’s no way around it. And figuring out a root cause only helps if there’s some hope that the problem may be fixed. So why bother?
Anyway, I’ve got a Linux CD which could fix the issue once and for all.
[I just found this blog entry had been sitting in my drafts folder for over a year, better late than never, I guess]
As I was reading On PETA and Weekday Vegetarians, I was reminded of a story I heard a long time ago: A guy did a rolling stop at a stop sign, and immediately got pulled over. The police officer told him that he failed to stop, to which he answered “But I slowed down!” The officer ordered him out of the car, and began beating the man, after a few seconds of this, the officer asked “do you want me to slow down or stop?”
I guess Ingrid Newkirk would condemn the law’s “all or nothing” attitude about stop signs? But just like those who “bend the rules” at stop signs, her inability to tell the difference between stopping and slowing down is endangering far more animals. Her “all or nothing” strawman and her “screw the principle” attitude is leaving those who would try to go vegan adrift, with no clear destination; no clear reason for doing so. Such people may end up remaining vegan, or, more likely, they may end up buying grass-fed beef and cage free eggs and feeling that this somehow makes animals’ lives better.
I am certainly not denying that one must be pragmatic or that “all or nothing” is unreasonable. To combat something as deeply entrenched as our pervasive use of animals we have to take an incremental approach. But without a principle guiding us, we won’t know which increments to pursue. We won’t know where we are going. We have no hope of getting anywhere near “all”, we are more likely to wander aimlessly and end up with “nothing”.
The only way we will end animal suffering is to stop using them. That is the principle we must stick to. That isn’t to say that everyone must become 100% vegan tomorrow. If someone can be vegan on weekdays (or one day, or even one meal), that is a good thing, and a step in the right direction. But knowing the principle is what will make them take the next step.
Recently I attended the inaugural planning meeting for the Danbury Hackerspace. During the inevitable “why are you here” discussions, I stumbled through some impromptu thoughts on the subject, but I’d like to flesh out my thoughts here.
I spent the first 10 years of my life on a small farm. My father also spent his first 10 years on the same farm, but in the depths of the Great Depression. The echos of that experience reverberated throughout my own childhood. But I’m not talking about poverty or starvation, but rather about the resourcefulness and creativity of my ancestors in a situation where every commodity was precious; where, if you wanted something, you often had to make it yourself; if something broke, you had to fix it rather than throw it away and buy a new one. Many materials, which today would simply be thrown in the trash, were saved and reused in creative ways.

For example, I remember using a tool which was essentially a dowel, with a slit cut in it, and half of a large coffee can lid bolted in place and sharpened. We called it the “corn cutter” which is just what I used it for. My grandfather didn’t have the luxury of throwing away that scrap dowel and that tin can, and driving down to Home Depot to buy a machete. Another example is seen on the right: a toy top my grandfather made out of a spool of thread.
James Kunstler has said in his podcast that we are no longer a culture where people make things. On some level we, as a culture, decided it would be better to sell each other mortgage-backed securities than to actually make things. So we spent the last several generations forgetting all the skills our ancestors needed to simply live their lives. I am sure that I could come up with a long list of skills my grandparents had which I know nothing about. This becomes apparent to me as I try to maintain my own house and garden; I keep running into problems which I know that they must have solved.
Now it is true I, and others of recent generations, have a variety of skills which my ancestors utterly lacked. However, depending on how peak oil plays out, many of those skills could be irrelevant. When we lost power last year, my ability to program a computer suddenly became moot in the face of trying to ensure my family had water. So, we might all be facing the prospect of suddenly having to relearn these lost skills.
My daughter is now 3 and a half years old and, as every parent does, I have my collection of hopes and fears for her future. I want her to grow up in a world where people make things, where people help each other; not in a world where all things, even people, are disposable, and everybody just waits for someone else to fix things.
The recent hackerspace movement, and the possibility of getting one set up in the neighboring city, gives me some hope. If you’re in the vicinity, come to the next meetup; lets get this thing off the ground.
When I was a child, my parents would often tell me to repeat what they just told me, since I usually wasn’t paying attention. Now I have to do the same thing with my own daughter. Payback time, it seems.
But this blog entry isn’t about parenting, it’s about error messages.
I was just writing some code and realized that an important rule when writing error messages is to repeat back what the user said. There are many violations of this rule, the first one that comes to mind is this one from Windows:
The system cannot find the path specified.
That error may be comprehensible if you just typed a command, but as part of a script, it will be entirely useless. Obviously, the pathname needs to be displayed (of course, we still don’t know what was being done, or why).
This becomes even more important when a user specified value is modified in some way. For example I had a command line argument which could take a list. After breaking the list apart, I needed to validate the entries in the list. If I found anything invalid I could have simply given the error “invalid parameter”. Useless! Rather, I filtered out the valid values and then printed out the offending ones: “invalid parameters: a,b,c”.
Now, repeat what I just said!
The more I work with Perforce the more I dislike it. I just wasted over an hour of my life doing what should be a trivial action: adding a user.
At this point a parenthetical rant is needed: I don’t think the administrator of an SCM system should have to do such things. User management should be an IT issue, and the project owner should be in charge of who can access their repositories. The SCM administrator should just be in charge of making sure the system is set up such that that is the case.
Since this Perforce server it at its licensed user limit, I have to first delete a user to make room. That should be a trivial operation, right?
$ p4 user -f -d jdoe
User jdoe has file(s) open on 1 client(s) and can't be deleted.
Huh? I don’t care about open files! Clearly the word “force” (the -f option) is being used in some strange way. Since there isn’t a “really force this damn deletion” option, I have find the open file. First look for the users “client”:
$ p4 clients -u jdoe
$
There are none? Obviously we have “client” sharing going on (I’ll leave that for another rant). Logically, I should be able to get a list of files this person has opened, but expecting logical behavior is, apparently, unrealistic:
$ p4 opened -u jdoe
Usage: opened [ -a -c changelist# -C client -m max ] [ files... ]
Invalid option: -u.
That’s fine, I can use grep, even though it could be imprecise. For example, imagine that we had a person named James Ava, greping for “java” could yield countless false positives. Nevertheless, forging ahead:
$ p4 opened -a | grep jdoe
//depot/projects/releases/Something/3.14/src/ugh.c#5 - edit default change (xtext) by jdoe@goose
Sure enough, the client “goose” is owned by a different person who is active, so I can’t just delete it. Fortunately, I found another technote saying how to do this, so I do what it says:
$ p4 login jdoe
User jdoe logged in.
$ p4 -u jdoe -c goose -H goose.example.com revert -k //depot/projects/releases/Something/3.14/src/ugh.c
You don't have permission for this operation.
What?! I am the administrator. Super user. I have permission to do anything! So here we get to my usual pet peeve: lousy error messages. Even if we took the error message at face value, it is unhelpful since it doesn’t say what permission I need (besides “super”, that is). But the error message is undoubtedly incorrect, it is more likely that the server is refusing for some unrelated reason, but, due to poor programming, that generic error message is displayed.
Of course, even if that latter command worked it begs the question, why do I have to do all this menial work? This should all be rolled into a single command. It could be rolled into a script if the “revert” command, above, worked correctly.
I want those two hours of my life back. I could have used them more profitably working on the Perforce to SVN converter, and using it to get people off Perforce.
Another nice one from Thunderbird:

The hex number is a nice touch: provide the illusion of being specific and helpful while not actually doing so. The suggestion to contact a system administrator is a good one, as misery loves company.
The new installer for ClearCase is a mess in many ways, but this error made me cringe:
System kernel was failed to build properly and as a result MVFS was not loaded.
The bad grammar and missing punctuation are just a little extra insult to the injury of not being told HOW the kernel build failed, or, perhaps better yet, what to do about it.
This seems to keep happening to me: I get caught up in a lot of other things in life and never quite get around to my blog. Then after a year or so of inactivity, I suddenly remember it, update the software (now running trunk!) and start posting again. Let’s see how long I can keep it going this time. I’ve got a bunch of mostly written drafts in the queue so expect them soon.
Winter here has been brutal, and while it has slackened up quite a bit, I still have a thick blanket of snow (about a foot is my guess). A couple of weeks ago I started thinking about getting the garden started this year, and got several books both on indoor and outdoor plants. I also started finding gardening blogs one of the first ones I found, Your Small Kitchen Garden, was doing a seed giveaway, I signed up and forgot about it. But yesterday I got a letter from an address I didn’t recognize and opened it to find this:

So, a big thank you to Daniel for these seeds! I’m looking forward to getting these started… I’ve got two new hanging tomato planters that I got last fall (on clearance) and now I know what I’m putting in them.
NOTE: I started writing this on 22-Jul-2004, tranferred it to my personal wiki on 15-Oct-2006 and the last edit was on 4-Feb-2011 (except for an update and formatting fixes).
I have been working with ClearCase since 1994 and have become very familiar with its problems and shortcomings. I am using this page to accumulate a list of what is wrong, broken, or sub-optimal with ClearCase. This page has been written gradually over several years, often when I was in a bad mood after running into a problem. There are a number of good features of ClearCase which are not included in this page, but that information is readily available from IBM marketing.
Update: I attended the IBM Rational User’s conference in Jun 2007, and it appears that some of these problems are finally getting addressed. Version 8.0 should be sweet. I just hope I can hold out until mid 2009.
Another Update: It is now mid 2010 and no sign of version 8.0, and version 7.1 broke the installer such that we have yet to upgrade. My hope was obviously misplaced.
Final Update (July 2022): A reorg at my company moved me out of the team maintaining ClearCase so I no longer touch it.
Not Final Update (Oct 2025): Another reorg laid off the last ClearCase admin, and two managers above him, so I returned to doing ClearCase admin, with a crumbling and poorly-documented infrastructure.
If I had a nickel for every time someone complained to me about ClearCase performance I could have retired by now. The network architecture of ClearCase assumes that all users will be accessing the vob server via a high-speed local LAN. This is because most ClearCase operations require a huge number of round-trips between the vob server and the client.
I did some rough measurements of the packets exchanged during common operations and found that a simple “desc” operation takes over 100 round-trips, a “checkout” takes over 500 round-trips, and a “checkin” requires over 1000 round-trips.
I also did a comparison of creating a snapshot view and doing an initial checkout from SVN of an identical source tree. Subversion took about 49 round trips, but Clearcase did 117-144. Due to this latency difference it took 19 seconds to pull the source from Google code (through an https proxy), but it took 30 seconds to pull the source from a neighboring site over the intranet.
Clearly, even the slightest increase in latency between these hosts will mean a huge performance degradation. According to It’s the Latency, Stupid! the theoretical minimum latency for between machines on opposite shores of the USA is 42ms, in Siebel it seems to be about 62ms… that translates to a minimum checkin time of 62 seconds and that does not account for any processing time on any of the involved machines.
Both albd and the lock manager are single-threaded. This means that for a large user population you must have multiple servers in order to get reasonable performance. Update: it appears that the lock manager has been fixed in ClearCase 7.0.
Access control is very limited. It uses the old Unix model: user/group/other. If you have a vob which must be restricted to the members of two different groups, you will be in trouble. The suggestion always given by IBM is to create different regions for different user populations, but that suffers from the same multi-group issue, not to mention that a machine’s region can be changed.
I implemented rudimentary access control by applying an ACL on the vob storage directory. This prevents Windows users from mounting the vobs. Unfortunately, since vob mounting on Unix is done by root, those ACLs are ignored.
Update: Version 8.0 should include ACLs! Version 7.0.1 has a group to region mapping mechanism which is a reasonable stop-gap for CCRC until then.
In one sense this is the greatest feature of ClearCase: creation of a view (a.k.a. workspace) is a constant-time operation, i.e. creating a view for a 1mb source tree takes the same amount of time as for a 1tb source tree. Most source control systems require you to have a copy of every file on your local disk, which can be prohibitive for large source trees, both in terms of time and space.
But, here’s the rub: This means ClearCase lets you avoid careful segmentation/componentization of a product, instead developers can throw everything into one big source tree. But who cares? Since dynamic views are so cheap, it doesn’t matter, right? Wrong! When the source tree becomes so big that snapshots are no longer possible there are big downsides:
Like dynamic views, config specs are a mixed bag. They are a powerful and incredibly flexible mechanism for specifying what versions you want to look at. I find that understanding config specs is the central piece of knowledge you must have to effectively use ClearCase.
The problem with this is that it gives you a lot of rope. Plenty to hang yourself, though with enough slack that you won’t notice until much later (usually after a lot of damage is done).
So, people often hack their config specs, usually in an effort to avoid a merge, for example something like this:
element * .../mybranch/LATEST
element * .../otherbranch/LATEST
element * .../anotherbranch/LATEST
...
As long as those three branches are on non-overlapping sets of files, which are based on the same code base (e.g. label) this will usually work fine. But as soon as there is overlap, files must be merged. So much for avoiding the merge. Except now the situation is worse, now the merge must be carefully done in the right order. If, using the example above, the file foo.c has been changed on all three branches, a merge must take place from “anotherbranch” to “otherbranch”, and then a merge must take place from “otherbranch” to “mybranch”. Until that is done the source tree is out of whack.
Another reason people will modify config specs is to “fix” them. For example a whole team is using a config spec which has a timestamp. Someone notices that the timestamp has no timezone and is thus ambiguous. That person “fixes” the timestamp, but now is out-of-sync with the rest of the team. Then when that person branches a file, it may be off the wrong version. For this reason, I always tell people that consistency is more important than correctness.
The other problem with config specs is that it is the sole documentation as to the relationship between a branch and the code base.
The ClearCase Web interface has been included with the product for many years and is still severely limited. One of these limitations is that interactive triggers will not work. It seems like this would have simply have been a matter of making “clearprompt” understand that it is being run via the web interface and interoperate with it. But they didn’t bother with that (see the “Triggers” section for further criticism of clearprompt). Upon testing with our extensive set of triggers (only one of which is “interactive”, we find that “describe” does not work, so their documentation is dead wrong: it’s not “interactive” triggers that won’t work, but, indeed, triggers that call most any external clearcase command. I know that numerous companies use triggers for policy enforcement, to throw all those out the window to use the ClearCase Web interface is absurd.
Update: Version 7.0.1 seems to fix this so that almost all triggers work (those that modify the source file are said not to work). Even “clearprompt” seems to work.
It’s really too bad, because had AJAX been around when this was written they could have made a fairly nice interface, I’ll bet.
What a fantastic idea! Replace the clunky web interface (see above) with a small Java application which talks to the same server, and gives you decent performance even over a slow WAN connection. Unfortunately, the idea was kind of half-baked. There are tons of bugs, among them:
Some of these problems may be mitigated by 7.1, but it appears the server has been entirely rewritten in a way that will most hamper upgrade efforts.
In any given version control system, a “trigger” could be run on the client or on the server. Subversion took the latter option, ClearCase, the former. Both approaches have their downsides, but running them on the client have several severe downsides.
The first is that security is nearly impossible in an environment where users can manipulate their workstations. For example, many years ago, I had a trigger which simply ran “false” in order to make the operation fail. To get around that, one clever person replaced /bin/false with /bin/true, fortunately, he forgot to put it back and this is how we caught him. Had this person been a bit more careful, there would have been no way of knowing how his checkin got in despite the trigger.
The second downside is portability. There are a number of platforms on which the trigger must run, and throwing Windows into the mix makes this an even greater challenge. This leaves several options, all bad:
The first option would quickly became a nightmare of keeping duplicate scripts in sync in all but the simplest of triggers. The third option is obviously a huge performance hit, and in a system which is already renowned for slowness, would be extremely unwise.
I took the second option, and wrote an elaborate trigger infrastructure to work around all the platform foibles and perl anachronisms. It’s about 4000 lines of perl (including perldoc). But, even so, there are a myriad of ways in which a trigger can fail.
Now the good part of client-side triggers is that it is more scalable. It is better to have a trigger running on each person’s machine rather than have all of them running on a server.
Displaying good error messages is very difficult since the UI on Windows loses the output generated by the triggers, as does the web interface (though I think 7.x improved this). Therefore I took to using “clearprompt”, but it is very ill suited for displaying long (a.k.a. informative) messages, the text ends up wrapped in odd ways and often chopped off. Furthermore you can’t select text from it (say, for a URL).
Oh, and I discovered a serious problem many years ago. When do a triggerable action, ClearCase searches for all applicable triggers and builds a list, during which the vob is in a semi-locked state. If you have hundreds of triggers, this can cause all kinds of problems. Admittedly, it was not smart to have that many triggers, and it was easily fixed.
Also, see Web Interface section above.
In pre-MultiSite days, if you had development at multiple sites, someone was going to be stuck accessing a vob via a WAN, which is unacceptably slow (see performance section above). MultiSite promised to fix that by allowing vobs to be replicated between sites, such that each site would have local copies of each vob. It sounded wonderful, and my employer at the time (Informix) was lobbying hard for this product and were one of the first to deploy it.
Sadly, there was a hitch: mastership. MultiSite makes a key assumption:
In all my years I have never seen such a situation, and over the years teams have become more widely distributed. As such, “mastership” was troublesome for administrator, and confusing for users.
In order to mitigate this explicit mastership was introduced (in v3, I think). So now mastership of a branch could be moved around on different files. This is an improvement given the following assumption:
Strike two. There are always files that multiple teams need to modify. Furthermore, this sort of mastership is confusing.
Next, request mastership was introduced, which allowed users to request mastership for a given branch or branch instance. This seems like a good idea, but there are several problems:
Here’s a different problem: When packets are being imported each action has to be replayed. Normally this is quick… but if the packet contains 50,000 mklabel commands, your MultiSite queues become jammed. (See the Labeling section)
And another issue: The entire vob database and source pools are replicated, even though it is rare for a remote site to use more than a few branches/versions. 90% of what’s being replicated is of no interest to a given site. As I understand it, Perforce has a better replication strategy where local replicas simply cache what is used locally, which would be a much smarter way of doing things.
There is no formal relationship between a branch and its base point, that key bit of information is in the config spec. So, given a branch name, there is no way to find out the base of the branch without asking someone. Guessing is a sure way to run into trouble.
Now, this is actually a feature since it means that the base point can be changed, which is a great optimization of the merge process. For example, given the following branch structure:
dev -------o
/
main --------o----------o
C1 C2
So, this means the “dev” branch was created based on the “C1” checkpoint. Let*s assume that 100 files have been changed on the “dev” branch, but, on main 1000 files have been changed between “C1” and “C2”. If you do a merge from “C2” to the “dev” branch (which seems an intuitive way of rebasing) you will bring 1000 files into your “dev” branch. This means that another 1000 files will need to be merged from now on. However, if first change your config spec to base “dev” on “C2” and then do a merge from “C2”, you have done the same thing except you will only merge files which have been changed on both branches (which will be 100 or less).
While the merge tools with ClearCase are some of the best I have seen, there are several key shortcomings:
Labels are a linear-time operation (O(n), for CS types), that is, the time taken is proportional to the number of elements being labeled. The fastest labeling rate I ever saw was about 25 files per second. For small source trees this is irrelevant, but for large ones it is insanely slow (see the Dynamic View section about large source trees). This can be mitigated to a certain degree by running the mklabel commands in parallel.
Furthermore, in a MultiSite environment, the update packets containing these mklabel commands clog things up since MultiSite replays these events at about the same pace they took to run in the first place. This clog can be made worse by labeling in parallel as suggested above.
Of course, using timestamps in a config spec can work just as well as a label, providing the engineering managers are willing to accept such a thing.
There should be a new type of label, which is really just a config spec excerpt, which would, in turn contain a branch and timestamp.
When view profiles first appeared (in v3, I think), it seemed like it might address some problems with config specs. However after working with them for several years, they seem like more of a hindrance than a help. First off they are not portable to Unix; what is truly astounding about this mistake is that simply using forward slashes instead of backwards slashes would have done the trick. Though this portability is further hindered by the software’s inability to handle Unix line endings. Secondly, there is no command line interface, which means if you want your build scripts to use the same view profile that developers use, you have to cook up a wrapper to do so (my ClearCase::ConfigSpec perl module does so). It is nice that it gives you an easy, graphical way to create branches and deliver changes from them, however, this UI is missing a key feature: rebasing! How could such an essential feature have been forgotten?
It also astounds me that a product that specializes in version control would write the view profile mechanism so that is exceedingly hard to incorporate into a VOB. I spent a lot of time figuring out how to check in view profiles and distribute them to all sites.
Also, the if a view is associated with a view profile mechanism, all relevant vobs should be automatically mounted when the view is started. A great feature! However, it doesn’t work much of the time, though no errors are recorded as to why.
Another problem is that the automatically generated private branch config specs use the old, cumbersome, -mkbranch modifiers, rather than the mkbranch rule. Furthermore, they neglected to include the “-override” modifier which would have greatly simplified how they set up the private branch config specs.
It seems to me that the view profile mechanism was written by someone who knew nothing of Windows/Unix portability, version control, the command line, recent config spec features or typical branch/merge techniques.
Of course, this all begs the question as to why they didn’t simply extend the config spec mechanism to include vob lists and the like? They extended it for snapshot views…
As noted above, snapshot views can be slow to populate due to the number of round-trips required. For large source trees, it can be prohibitively slow. With some systems (like visual sourcesafe) this could be mitigated by running many updates in parallel on different directories, but, unfortunately, that is out of the question for ClearCase as the snapshot view update is single-threaded and will not permit more than one to be running at a time.
When I first read about clearmake and derived objects, I thought it was of the cleverest ideas I had seen. However, I have never been able to use it in practice. The only way to use it is to rewrite all your makefiles using their old generic dialect of Make.
Furthermore, the disk space requirements can be rather onerous, since a single old view can cause many old derived objects to be retained. So, to avoid an explosion of disk usage, frequent audits have to be run and users constantly pestered about old views.
TBD… line endings
The region synchronizer is dumb, it doesn’t understand when to use -gpath/-hpath for a vob on a NAS, and, worst of all, it is a windows-only ui, which means I had to write a custom script to do automated vob tagging.
In ClearCase v4 a new “Scheduler” system was introduced, which purported to “fix” many of the problems with cron. However, in practice it is a very cumbersome system. The first problem is that current job status and schedule information is mashed together into one “configuration file”, which makes version control of these files very tricky (it is odd for a company which specializes in version control to prevent its use). The job numbers are problematic and redundant (why not just use a job name?). Creating a new job is tricky as there are so many entries that you have to set up. You cannot tell from the sched file what command will be run. That is stored in another file which cannot be modified via the “sched” command! It appears as though this is a system which expects to be manipulated via a GUI, but in the years that this system has been in existence, so such GUI has surfaced.
Most version control systems I know off (e.g. CVS, SVN, VSS, RCS, SCCS, &c.) will expand certain keywords (like $Header$) inside text files to contain information about the version of the file being looked at. This is essential for identifying which files/versions contributed to a given version of a product. However ClearCase has no such thing. It is often suggested to implement this via a trigger. The problem is that this trigger will cause any non-trivial merge to be a conflicting merge, since the same line has been modified on both branches.
Some then suggested that a type manager be set up to help with this. This is a good idea except for one thing: there is no mechanism for deploying type managers. Every client needs to have the new type manager. That’s not happening with over 1000 clients.
Such a type manager should have been a stock part of ClearCase from the beginning.
I brought up a big issue with type managers in the previous section. Another problem, is that the type manager mechanism confuses two separate concepts: How the versions are stored and how differences will be presented.
Case in point: the “ms_word” type manager is based on “file”, which will store full copies of every version. Often, the old versions of word documents are rarely going to be used, so devoting all that disk space to them is dumb. I could convert the element type to “binary_delta_file”, but that would lose the MS Word diff magic.
This is not unique to ClearCase, by any means; programmers should be ashamed of the poorly written, uninformative or downright misleading error messages that have become commonplace. Any error message should answer the usual set of questions: who? what? when? how? why? That means it should include all relevant file names, the reason for the failure, identity information (if relevant), and, ideally, some hint as to how to fix it.
Here is a little error message “hall of shame”:
I had high hopes for post 7.0 versions after attending the IBM Rational User’s conference in Jun 2007, though their predictions of future releases was overly optimistic. But upon getting version 7.1 I found the installer had been replaced by a new installer, which was a confusing mess. All the initial documentation seemed to assume that all installations would be done via a UI, which seems to indicate they forgot that most people have headless servers. The documentation on how to set up release areas and set up “silent installs” is hopelessly scattered and confusing. It is telling that the best information I have found about this comes from outside IBM.
This is a classic case of not following the maxim “if it ain’t broke, don’t fix it.” The old installer may have been a bit klunky but it worked! I’m betting this is the work of some clueless pointy-haired IBM executive who demanded that ClearCase be brought into conformance with other IBM products. To what degree this effort has distracted engineers from actually improving the product has yet to be seen, since a year after 7.1 was released, my team has just now gotten an installation to work, and are nowhere near figuring out how to deploy this to production servers.
I already mentioned the poor security with triggers, but the basic infrastructure of ClearCase is almost impossible to secure. The basic architecture is a nightmare from a security perspective. Everything is unencrypted (though perhaps SMB and NFS could be configured with encryption), and it uses random ports above 1024. Before you say, “oh but clients will always use random ports”, I am talking about the server side. The way it works is that the client will send a request to ALBD on port 373, and for most requests it will then respond with a port number, on which the server is awaiting the client to connect.
Every time I have told internal security teams about this, they do a google search and find a page which tells them to set CLEARCASE_MIN_PORT and CLEARCASE_MAX_PORT. But that page is somewhere between misleading and wrong. I have repeatedly tested this, it does not work, except for the MultiSite shipping server.
So this means any firewall, or, indeed any blocked port, between the client and server will break ClearCase. For example, many years ago the IT department blocked several ports used by viruses/worms. Every now and then the random port selection above would select that port. At which point the client would time out. Repeating the command would work. It was very non-deterministic. In order to work around this, I wrote a simple perl script to hold those ports open on the server, which would prevent ALBD from trying to use them.
cleartool: Error: Nonmastered checkouts are not permitted in unreplicated VOBs; pathname: "L:/ccperf_sdc78322svod_tfisher//cm_test_sun/somefile.cpp"
Here’s my take on the state of ClearCase: Around the time that Rational took over ClearCase (1998, I think) the core product stagnated entirely. There were no significant bug fixes or improvements since that time. Note that most of the problems I mention above have been like that for 10 years. A few new things were added but they all seemed botched in that they left part of the product out, or didn’t support all platforms (plenty of examples above). When IBM took over, I had hoped that they would shake things up, and it seems that in the last year or so they have. But I fear it may be too late. I have seen many teams abandon ClearCase out of frustration and competitive products pop up in the mean time (e.g. Subversion), and, to be honest, I’m not entirely sad about that since I am tired of being the messenger that everybody shoots at.
I have seen a number of Facebook friends join the cause NO DOG SHOULD BE BEATEN, and then I got an invite. Should I join or not? Of course, I cannot disagree with such a sentiment. However, it feels a bit odd. It would be like saying “No 4 year old Connecticut girls should get beaten with yardsticks”. Again, something very few people would disagree with, but far too specific.
If we widen the sentiment out to all animals, dogs, human or otherwise, that is better. Then replace “beaten” with “harmed in any way”. That sounds much better to me. But, I doubt that cause will get 1.3 million members, as it would require them to look at what is on their plate and realize they have to do something more than click the “join” button.
Very early in my career as a programmer, someone gave me advice that I needed to aim for the “ninety percent solution”, in other words, don’t waste time trying to get the perfect 100% solution. Tom Cargill of Bell Labs provided a concise explanation: “The first 90 percent of the code accounts for the first 90 percent of the development time. The remaining 10 percent of the code accounts for the other 90 percent of the development time.” This is analogous to the problem of distilling ethanol, getting it 97% pure isn’t too hard to do, but going beyond that takes enormous amounts of energy, and normally isn’t worth it (that is based on fuzzy memories of college chemistry class, so forgive any technical inaccuracies).
Recently I have read a number of articles which remind me that veganism can fall prey to this 90% rule. There are a number of reasons why one may become vegan: health, environment, animal welfare and animal rights (I exclude the “imitating a celebrity” reasons that PETA works towards, as that’s never a good reason for doing anything). The problem is that all but one of those reasons can only get you to 90%.
When I first became vegan it was for health reasons. So when a friend of mine told me that “a little steak now and then won’t kill you,” I had no good answer to this. He was right. I could eat a steak right now, and the impact on my long term health would be negligible. In other words, there was little difference between being 100% or 90% vegan, when looking at the health arguments. See How the Health Argument Fails Veganism for more about this.
Being vegan for environmental reasons suffers the same problem, as the mis-titled article Veggieworld: Why eating greens won’t save the Planet shows. If your concern is the environment, being 90% vegan is a pretty clear win. But arguing for that last 10% can be very hard. So “a little steak now and then won’t kill the planet.”
As the recent decades have shown us, the animal welfare arguments also suffer from this problem. Someone who is vegan because of how animals are treated, when presented with the flesh of an animal who was free-range, fed organic feed, and was gently asphyxiated with a gold-lined silk scarf at the moment of orgasm, they would have a hard time refusing. Thus we see the parade of now-ex-vegans marching into Whole Foods to buy their “happy meat” with a clear conscience. Or so they think.
So, finally we arrive at the animal rights position. Gary Francione presents the clearest, most consistent and most concise presentation of this position: “We have no moral justification for using nonhumans for our purposes.” Here we have the 100% solution we’ve been looking for. This is where we all need to start when we tell people why we are vegan. And why they should be vegan. And why you should be vegan.
I just read the article Why I Hate Telling People I’m Vegan, and I can partially understand the frustration with the barage of questions (often silly) and nutritional misconceptions. Go play some bingo to get a sampling. When I first became vegan, I often wouldn’t have clear answers in these situations and dreaded them. Over the years I’ve read enough that I can now address many of these questions.
However, there is a passage in this article which begs the question “why are you vegan?”
Raise the beef, cut it up… sell it. Fine by me. I have no problem with what you’re doing, I simply choose not to partake.
I might have said the same thing years ago, largely because I became vegan, initially, for health reasons, which makes such a decision a personal one. Thankfully within a few years I heard an interview with Gary Francione, which provided a simple and compelling reason for being vegan.
So if I were in the same situation as the author of the above passage, my thought process would go like this: “I can’t stop you from raising the cow, killing it, cutting it up and selling it. I consider this immoral behavior, and I have a big problem with it.” But saying that out loud won’t gain any friends, let alone converts, so such situations must be handled with delicacy.
But the more interesting passage was amongst the comments, by the same author:
I mean, can you imagine if meat-eaters evangelized about their diets? Vegans would have an absolute fit - sprouts and farrow flying willy-nilly out of their re-usable Whole Foods bags! Yipes!
Setting aside the dismissive, stereotyping imagery, the fact is that meat-eaters are evangelizing all the time. We are bombarded by it on every billboard, in every aisle of the grocery store, on every restaurant menu, &c. (see the Suicide Food blog displays some of the more egregious cases). I have had many conversations with meat-eaters who were clearly bothered by my veganism and were determined to find an inconsistency in hopes that they could justify their behavior and, hopefully, bring me back into the fold. In short, evangelizing. The evangelizing is such a constant part of the background noise of life, that many, like the author above, are not even aware of it.
Here’s one from Chrome:

Cute icon! Funny phrase! I guess those are supposed to distract us from the total uselessness of the error message.
A while back I happened upon a “defensive omnivore bingo” card at veganporn, I then found the original, a revised version, a more artistic version, a feminist version, and many reposts.
As an exercise for learning Jquery, I wrote a javascript enabled version which picks random statements from a long list including ones from the versions above and some of my own. I started to add answers to some of the statements in popups. You can even place chips on the squares (by clicking), but the “bingo” is entirely anti-climactic. I actually started writing this months ago, but I just worked out a couple of annoying bugs. Feel free to send me any suggestions for additional statements and/or answers.
Back in 1992 or so I was writing an email-based trouble-ticket system which tried to match up incoming emails to existing trouble-tickets by looking at the In-Reply-To: email header. Much to my chagrin, I found that a few email programs did not add this header when replying to messages. So I had to add a set of kludges to hook together tasks that were mistakenly broken by such email messages, and some subject-line shenanigans to allow tasks to be manually specified.
Well, in those days, email was a new thing, and so some amount of ignorance was understandable. 20 years later, we have managed to add those couple of lines of code into every email program, right? Such hope is misplaced. While wrestling to get threading to work properly in Thunderbird, I find that it is still a problem! Viz, “The bad news is that not all e-mail clients actually generate these message headers.” Now we aren’t talking about some ancient text-based email programs (ironically, they all got it right back in 1992, it was the Mac which was broken), the example given in the next sentence is Yahoo!
While, I know, first hand, about dealing with these sort of broken email threads, it is sad that Thunderbird cannot get it right; none of the semi-hidden settings allow it to join together the multitude of broken email threads in my inbox.
The key to working with computers, it seems, is lowering your expectations.
I got this error, which definitely wins the quantity over quality prize:
23:56:50,545 [main] INFO historyLogger:84 - EXCEPTION CAUGHT: org.polarion.svnimporter.ccprovider.CCException: java.io.IOException: No space left on device
at org.polarion.svnimporter.ccprovider.internal.CCContentRetriever.getContent(CCContentRetriever.java:94)
at org.polarion.svnimporter.svnprovider.internal.actions.SvnAddFile.calculateLengthAndChecksum(SvnAddFile.java:104)
at org.polarion.svnimporter.svnprovider.internal.actions.SvnAddFile.dump(SvnAddFile.java:83)
at org.polarion.svnimporter.svnprovider.internal.SvnRevision.dump(SvnRevision.java:127)
at org.polarion.svnimporter.svnprovider.SvnDump.dump(SvnDump.java:191)
at org.polarion.svnimporter.main.Main.saveDump(Main.java:221)
at org.polarion.svnimporter.main.Main.run(Main.java:91)
at org.polarion.svnimporter.main.Main.main(Main.java:49)
Caused by: java.io.IOException: No space left on device
at java.io.FileOutputStream.writeBytes(Native Method)
at java.io.FileOutputStream.write(FileOutputStream.java:260)
at org.polarion.svnimporter.common.Util.copy(Util.java:303)
at org.polarion.svnimporter.common.FileCache.put(FileCache.java:72)
at org.polarion.svnimporter.common.FileCache.put(FileCache.java:87)
at org.polarion.svnimporter.ccprovider.internal.CCContentRetriever.getContent(CCContentRetriever.java:90)
at org.polarion.svnimporter.svnprovider.internal.actions.SvnAddFile.calculateLengthAndChecksum(SvnAddFile.java:104)
at org.polarion.svnimporter.svnprovider.internal.actions.SvnAddFile.dump(SvnAddFile.java:83)
at org.polarion.svnimporter.svnprovider.internal.SvnRevision.dump(SvnRevision.java:127)
at org.polarion.svnimporter.svnprovider.SvnDump.dump(SvnDump.java:191)
at org.polarion.svnimporter.main.Main.saveDump(Main.java:221)
at org.polarion.svnimporter.main.Main.run(Main.java:91)
at org.polarion.svnimporter.main.Main.main(Main.java:49)
So, after that deluge of “information”, all I know that I ran out of space on a filesystem. Which filesystem, you ask? If they told us that would ruin the fun of this guessing game!
The stack trace is a nice touch, since it provides little useful information, like what parameters were being passed, etc. I used to display stack traces like this for my own programs, but have stopped doing so as they didn’t provide as much information as a well-written error message. This stack trace is much like driving directions which consist solely of the phrases “turn right” and “turn left”, but no street names, distances or landmarks. Largely useless.